Appearance
1. Commit log
Trong Cassandra, commit log là một thành phần quan trọng trong quá trình ghi dữ liệu.
Khi một bản ghi được ghi vào Cassandra, nó sẽ được ghi vào commit log trước tiên.
Commit log là một file tuần tự, có nghĩa là các bản ghi được ghi vào cuối file theo thứ tự thời gian.
Commit log đảm bảo rằng dữ liệu không bị mất trong trường hợp hệ thống gặp sự cố.
Nếu một node Cassandra gặp sự cố, commit log có thể được sử dụng để phục hồi dữ liệu đã ghi trước đó.
Commit log được sử dụng để ghi lại tất cả các thay đổi đối với dữ liệu trong Cassandra.
Quá trình khôi phục dữ liệu từ commit log
Khi một node Cassandra khởi động lại, nó sẽ đọc commit log để phục hồi dữ liệu đã ghi trước đó.
Khi Cassandra khởi động lại sau một sự cố hoặc khởi động lại bình thường, nó sẽ đọc commit log để phục hồi bất kỳ bản ghi nào chưa được flush từ Memtable xuống SSTable.
Quá trình này giúp đảm bảo không có dữ liệu nào bị mất.
Lưu ý: Cassandra vẫn phục hồi dữ liệu lên Memtable trước.
2. Memtable
Memtable là một cấu trúc dữ liệu trong bộ nhớ, nơi dữ liệu được ghi vào trước khi được flush xuống đĩa dưới dạng SSTable.
Khi một bản ghi được ghi vào Cassandra, nó sẽ được ghi vào Memtable trước khi được flush xuống SSTable.
Khi Memtable đầy, nó sẽ được flush xuống SSTable và các commit log đã được memtable fush xuống SSTable sẽ được xóa để giảm bộ nhớ.
Memtable cho phép Cassandra ghi dữ liệu nhanh chóng mà không cần phải ghi trực tiếp xuống đĩa, giúp cải thiện hiệu suất ghi.
SSTable
SSTable (Sorted String Table) là một định dạng lưu trữ dữ liệu trên đĩa trong Cassandra.
Đây là file format dùng để lưu trữ dữ liệu đã được flush từ Memtable. Dữ liệu này sẽ được lưu an toàn trên đĩa và có thể được truy xuất khi cần thiết.
Các đặc điểm của SSTable
- Bất biến: Khi một SSTable đã được tạo ra và ghi xuống disk, nó không thay đổi. Mọi thay đổi như thêm, cập nhật hay xóa dữ liệu đều được xử lý thông qua tạo SSTable mới.
- Sắp xếp bởi khóa chính: Dữ liệu trong SSTable được lưu trữ theo thứ tự đã sắp xếp của khóa chính (Partition key). Điều này cho phép truy suất data dễ dàng.
- Chứa các metadata:
- Data: Dữ liệu thực tế được lưu trữ.
- Index: Chỉ mục để truy xuất dữ liệu nhanh chóng.
- Summary file: Là phiên bản rút gọn của index file, cho phép nhanh chóng tìm kiếm trong index file.
- Statistic file, Chứa metadata về SSTable, nhưng số lượng key, min và max key...
- Compression info file: Nếu dữ liệu được nén, file này chứa thông tin cần thiết để giải nén.
- TOC (Table of Contents) file: Liệt kê tất cả các thành phần của SSTable.
- Digest file: Chứa checksum của dữ liệu để kiểm tra tính toàn vẹn.
- Bloom filter file: Giúp xác định nhanh chóng xem một khóa có tồn tại trong SSTable hay không mà không cần phải đọc toàn bộ dữ liệu.
- Hỗ trợ Compaction: Cassandra sử dụng quá trình gọi là compaction để hợp nhất nhiều SSTable thành một SSTable lớn hơn, giúp giảm độ phân mảnh dữ liệu và cải thiện hiệu suất truy vấn.
- Compaction là quá trình hợp nhất nhiều SSTable thành một SSTable mới. Trong quá trình này, Cassandra sẽ kiểm tra và chỉ giữ lại phiên bản mới nhất của mỗi bản ghi (dựa trên timestamp).
- Các bản ghi cũ hơn và các bản ghi đã bị xóa (được đánh dấu là tombstones) sẽ được loại bỏ.
- Tombstones: Khi một bản ghi bị xóa, Cassandra không xóa bản ghi đó ngay lập tức khỏi SSTable. Thay vào đó, nó đánh dấu bản ghi đó là đã xóa bằng cách sử dụng một "tombstone". Tombstones cũng được xử lý trong quá trình compaction.
Tổng quan minh họa bằng hình ảnh
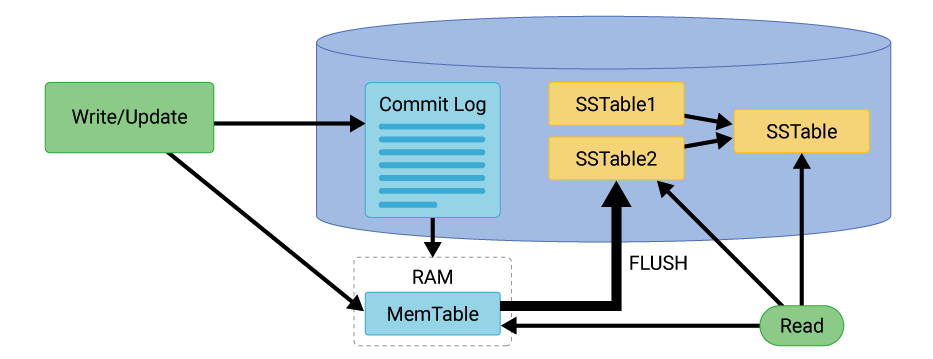
Mối quan hệ giữa Commit Log, Memtable và SSTable
Mối quan hệ giữa commit log, memtable và SSTable trong Cassandra có thể được mô tả như sau:
Quá trình ghi dữ liệu trong Cassandra
- Commit Log: Khi một bản ghi được ghi vào Cassandra, nó sẽ được ghi vào commit log trước tiên. Commit log là một file tuần tự, có nghĩa là các bản ghi được ghi vào cuối file theo thứ tự thời gian. Commit log đảm bảo rằng dữ liệu không bị mất trong trường hợp hệ thống gặp sự cố.
- Memtable: Sau khi bản ghi được ghi vào commit log, nó sẽ được ghi vào memtable. Memtable là một cấu trúc dữ liệu trong bộ nhớ, nơi dữ liệu được ghi vào trước khi được flush xuống đĩa dưới dạng SSTable. Memtable cho phép Cassandra ghi dữ liệu nhanh chóng mà không cần phải ghi trực tiếp xuống đĩa, giúp cải thiện hiệu suất ghi.
- SSTable: Khi memtable đầy, nó sẽ được flush xuống SSTable. SSTable là một định dạng lưu trữ dữ liệu trên đĩa trong Cassandra. Dữ liệu này sẽ được lưu an toàn trên đĩa và có thể được truy xuất khi cần thiết. SSTable chứa các bản ghi đã được flush từ memtable và được sắp xếp theo thứ tự đã sắp xếp của khóa chính (Partition key).
Quá trình khôi phục dữ liệu
- Khởi động lại: Khi một node Cassandra khởi động lại, nó sẽ đọc commit log để phục hồi dữ liệu đã ghi trước đó mà chưa được flush từ memtable xuống SSTable. Quá trình này giúp đảm bảo không có dữ liệu nào bị mất.
- Memtable: Sau khi đọc commit log, Cassandra sẽ phục hồi dữ liệu lên memtable. Memtable sẽ chứa các bản ghi đã được ghi vào commit log nhưng chưa được flush xuống SSTable.
- SSTable: Khi memtable đầy, nó sẽ được flush xuống SSTable. Các bản ghi trong memtable sẽ được ghi vào SSTable và commit log sẽ được cập nhật để phản ánh các bản ghi đã được flush.
Quá trình compaction
- Compaction: Cassandra sử dụng quá trình gọi là compaction để hợp nhất nhiều SSTable thành một SSTable lớn hơn. Trong quá trình này, Cassandra sẽ kiểm tra và chỉ giữ lại phiên bản mới nhất của mỗi bản ghi (dựa trên timestamp). Các bản ghi cũ hơn và các bản ghi đã bị xóa (được đánh dấu là tombstones) sẽ được loại bỏ.
- Tombstones: Khi một bản ghi bị xóa, Cassandra không xóa bản ghi đó ngay lập tức khỏi SSTable. Thay vào đó, nó đánh dấu bản ghi đó là đã xóa bằng cách sử dụng một "tombstone". Tombstones cũng được xử lý trong quá trình compaction.
Quá trình truy xuất dữ liệu
Khi truy vấn dữ liệu, Cassandra sử dụng một quá trình gọi là "read path" để xác định giá trị chính xác nhất của một bản ghi:
- Tìm kiếm trong Memtable: Cassandra sẽ kiểm tra memtable trước tiên để xem liệu bản ghi có tồn tại trong bộ nhớ hay không.
- Nếu bản ghi tồn tại trong memtable, nó sẽ trả về giá trị ngay lập tức.
- Bloom Filters: Nếu không tồn tại trong Memtable, Cassandra sử dụng Bloom filter để xác định xem SStable chứa bản ghi hoặc không SStable nào chứa bản ghi. Nếu Bloom filter cho thấy khóa không tồn tại, Cassandra sẽ không cần đọc SSTable, giúp tiết kiệm thời gian và tài nguyên.
- Bloom filters là cấu trúc dữ liệu cho phép kiểm tra nhanh chóng và hiệu quả liệu một phần tử có thuộc một tập hợp hay không.
- Bloom filter sẽ trả về hai kết quả:
- Có thể có: Điều này có nghĩa là phần tử có thể thuộc tập hợp, nhưng không chắc chắn.
- Chắc chắn không: Điều này có nghĩa là phần tử không thuộc tập hợp.
- Bloom filter sẽ trả về hai kết quả:
- Bloom filters là cấu trúc dữ liệu cho phép kiểm tra nhanh chóng và hiệu quả liệu một phần tử có thuộc một tập hợp hay không.
- Partition Summary và Partition Index: : Nếu Bloom filter cho thấy khóa có thể tồn tại, Cassandra sẽ sử dụng Partition Summary và Partition Index để xác định SSTable nào chứa bản ghi. Partition Summary là một phiên bản rút gọn của index file, giúp nhanh chóng tìm kiếm trong index file.
- SSTable: Cassandra sẽ đọc SSTable để lấy dữ liệu. Nếu bản ghi tồn tại, nó sẽ trả về giá trị của bản ghi. Nếu không, nó sẽ tiếp tục tìm kiếm trong các SSTable khác.

Cập nhật lần cuối: