Appearance
Khái niệm cốt lõi và mô hình dữ liệu.
Mục tiêu
- Hiểu kỹ về cấu trúc dữ liệu trong Cassandra (Keyspace, Table, Partition Key, Clustering Key, v.v.)
- Biết cách thiết kế lược đồ (schema) theo đặc thù phi quan hệ (NoSQL), tư duy partition, clustering.
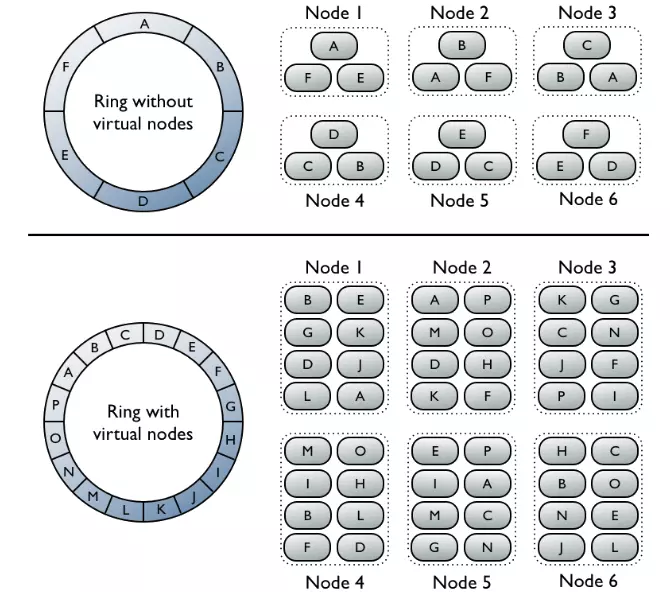
1. Hiểu kỹ về cấu trúc dữ liệu trong Cassandra
Trong Cassandra, dữ liệu có cách thành phần chính như sau:
- Keyspace
- Table
- Partition Key
- Clustering key
- Primary key
1.1 Keyspace
Keyspace là cấp độ cao nhất trong mô hình dữ liệu của Cassandra, Keyspace tương đương với Schema trong các database quan hệ.(VD: Mysql). Hiệu 1 cách đơn giản thì 1 Keyspace tương đương với tạo thêm một Database trên Mysql
Keyspace chứa các Table và xác định các cấu hình quan trọng cho Keyspace này.
- Replication Factor: Xác định số lượng bản sao của dữ liệu sẽ được lưu trữ trên các node khác nhau trong cluster.
- Ví dụ cùng 1 data sẽ được lưu ở trên 1 hoặc trên 5 node khác nhau. Số càng nhiều thì dữ liệu càng an toàn nhưng cũng sẽ tăng chi phí tài nguyên.
- Replication Strategy: Xác định cách các Replication được phân phối trên các Node.
- Simplate: Được dùng khi chỉ có một trung tâm dữ liệu duy nhất. Trong chiến lược này, replication đầu tiên được đặt trên node được xác định bởi Partitioner (Thường dùng hash để xác định). Các bản replication tiếp theo sẽ được lưu trữ trên node kế tiếp theo chiều kim đồng hồng bắt đầu từ node đầu tiên.
- NetworkTopologyStrategy: Được sử dụng khi chúng ta có nhiều trung tâm dữ liệu. Chiến lược này cho phép chúng ta xác định số lượng repilcation được lưu trữ trên mỗi trung tâm dữ liệu. Giúp tăng khả năng chịu lỗi.
Ví dụ:
CREATE KEYSPACE my_keyspace WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': 3
};Việc lựa chọn cấu hình phù hợp cho Keyspace là rất quan trọng, vì nó ảnh hưởng trực tiếp đến hiệu suất, khả năng chịu lỗi và tính sẵn sàng của hệ thống Cassandra.
1.2 Table
Trong Cassandra thì Table tương tự như table trong cơ sở dữ liệu quan hệ, nhưng có 1 số khác biệt quan trọng.
1.2.1 Primary key:
Chịu trách nghiệm phân phối dữ liệu trên các Node trong Cluster. Giá trị Partition sẽ được hash để xác định node nào lưu dữ liệu.
Có 2 loại Primary key là:
Simple Primary key: Chỉ bao gồm 1 column duy nhất.
CREATE TABLE users (
user_id UUID PRIMARY KEY,
name TEXT,
email TEXT
);Trong ví dụ này thì user_id sẽ là Primary key và nó cũng sẽ là Partition Key(sẽ giải thích ở dưới)
Composite Primary key
Với Composite Primary Key thì sẽ có nhiều column kết hợp với nhau để xác định Primary Key.
Tuy nhiên chỉ có column đầu tiên được sử dụng để xác định Partition Key.
CREATE TABLE orders (
order_id UUID,
customer_id UUID,
order_date TIMESTAMP,
PRIMARY KEY (customer_id, order_date)
);Trong ví dụ này thì chúng ta có một primary kết hợp là customer_id, order_date.
Trong đó customer_id sẽ được sử dụng để xác định Partition key, nơi dữ liệu được lưu.
Trong đó order_date là Clustering Key, xác định thứ tự sắp xếp của các Record trong cùng 1 partition.
Điều này có nghĩa là tất cả các đơn hàng của cùng một khách hàng (customer_id) sẽ được lưu trữ trong cùng một phân vùng và được sắp xếp theo order_date
Composite Partition Key
Chúng ta có thể kết hợp nhiều column để thành một một Partition Key để đảm bảo phấn phối dữ liệu đồng đều hơn.
CREATE TABLE sensor_data (
sensor_type TEXT,
sensor_id UUID,
timestamp TIMESTAMP,
value DOUBLE,
PRIMARY KEY ((sensor_type, sensor_id), timestamp, value)
);Trong ví dụ này. Hash của sensor_type, sensor_id sẽ được sử dụng để xác định partition key,
timestamp, value sẽ là Clustering Colum được sử dụng để xác định thứ tự sắp xếp của các hàng trong cùng một partition.
Clustering Key
Ở trên cũng đã nhắc đến rồi, Clustering Key sử dụng để xác định thứ tự sắp xếp của dữ liệu trong một partition. Nó giúp truy vấn dữ liệu theo một thứ tự cụ thể mà không cần sắp xếp lại.
CREATE TABLE blog_posts (
author TEXT,
post_id UUID,
title TEXT,
content TEXT,
PRIMARY KEY (author, post_id)
) WITH CLUSTERING ORDER BY (post_id DESC);1.3 Row
Bao gồm một tập hợp các cột được xác định bằng khoá chính duy nhất bao gồm partition key và các khoá bổ sung.
Một row bạn có thể hiểu là một hàng dữ liệu hoặc đọc là một Record dữ liệu.
Thực tế, khái niệm này the same với Mysql.
2. Cơ chế lưu trữ
2.1 Partition
Casandra sử dụng cơ chế partition để chia nhỏ dữ liệu và phân phối chúng đến các node trong Cluster. Quá trình này được thực hiện thông qua một hash method(Thường là Murmur3Partitioner) áp dụng lên Partition key để tạo ra một token.
Token này xác định vị trí của dữ liệu ở trong một vòng tròn cluster, đảm bảo rằng các dữ liệu có cùng partition key sẽ được lưu trữ cùng nhau trên 1 node.
Mỗi node trong cluster sẽ chịu trách nghiệm quản lý một hoặc nhiều token, tương ứng với các phân vùng dữ liệu. Khi một node bị xoá các token nó quản lý sẽ được phân phối lại cho node khác quản lý.
2.2. Replication Factor, chiến lược replication (SimpleStrategy, NetworkTopologyStrategy).
2.2.1 Replication Factor
Replication Factor là xác định số lượng bản sao của mỗi Record được lưu trữ trong Cluster. Ví dụ nếu nó =2 thì Mỗi Record sẽ có 2 bản sao trên các Node khác nhau.
2.2.2 chiến lược replication
Chiến lược replication, chúng ta sẽ xác định cách thức replication dữ liệu trên các node và trung tâm dữ liệu.
SimpleStrategy
Được thiết kế dành cho khi bạn chỉ có 1 trung tâm dữ liệu.
Với chiến lược này, bản sau dữ liệu đầu tiên được xác định bởi partitioner thông qua Hash. Các bản sao tiếp theo sẽ được đặt trên các node kế tiếp theo chiều kim đồng hồ mà không cần xem cấu trúc mạng.
NetworkTopologyStrategy
Được khuyến nghị cho hầu hết các triển khai, đặc biệt khi bạn đã dự kiến có nhiều trung tâm dữ liệu. Chiếc lược này cho phép bạn xác định số lượng bản sao muốn có trong mỗi trung tâm dữ liệu.
NetworkTopologyStrategy đặt các bản sao trong cùng một trung tâm dữ liệu và sao chép trên các node và trung tâm dữ liệu khác nhau. ĐIều này sẽ giúp tăng khả năng chịu lỗi.
Lưu ý: Khi quyết định số lượng bản sao sẽ được lưu trữ trong một trung tâm dữ liệu, cần cân nhắc khả năng đọc cục bộ mà không phụ thuộc vào độ trễ giữa các trung tâm dữ liệu và các kịch bản lỗi có thể xảy ra.
3. CQL (Cassandra Query Language)
Ngôn ngữ truy vấn(QL || Query Language) là một ngôn ngữ được sử dụng để thực hiện việc truy vấn trong cơ sở dữ liệu và hệ thống thông tin.
SQL(Structured Query Language) là ngôn ngữ truy vấn chuẩn để xử lý cơ sở dữ liệu quan hệ. Các ngôn ngữ truy vấn quan hệ thường dễ dàng mở rộng theo chiều dọc dựa trên table và được cố định bởi schema.
Các ngôn ngữ truy vấn NoSQL như CQL có thể truy vấn trên các cluster phân bổ theo chiều ngang và có khả năng mở rộng quy mô lớn, quản lý phi cấu trúc, không có schema cố định.
CQL (Cassandra Query Language) là gì?
Cassandra QL là QL chính được sử dụng để giao tiếp với cơ sở dữ liệu Cassandra.
Mặc dù Cassandra là một NoSQL nhưng CQL có cú pháp tương tự SQL nhưng được thiết kế dành riêng cho kiến trúc Cassandra. Được tối ưu hoá về hiệu suất.
Các đặc điểm chính của CQL:
- Cấu trúc table: Giống với database quan hệ nhưng không yêu cầu nghiêm ngặt dữ liệu.
- Có các định nghĩa schema: Có các định nghĩa giống schema CREATE TABLE, ALTER TABLE, DROP TABLE.
- Khoá chính(Primary key) và khoá phân trang (Partition Key): Khoá chính và khoá phân trang được sử dụng để hỗ trợ tìm kiếm nhanh và phân chia dữ liệu trên nhiều node.
- Không hỗ trợ join và hạn chế các phép toán tổng hợp dữ liệu(JOIN, GROUP BY)
- Việc join hoặc có các phép toán tổng hợp từ nhiều dữ liệu sẽ gây tốn chi phí. Vì vậy CQL không hỗ trợ các phép toán này.
- Hoạt động bất đồng bộ: Hỗ trợ ghi và đọc trên nhiều node cùng 1 thời điểm.
Ví dụ truy vấn CQL
Tạo table
sql
CREATE TABLE users (
id UUID PRIMARY KEY,
name TEXT,
age INT
);Chèn thêm dữ liệu
sql
INSERT INTO users (id, name, age) VALUES (uuid(), 'Alice', 25);Truy vấn dữ liệu
sql
SELECT * FROM users WHERE id = 123e4567-e89b-12d3-a456-426614174000;Xóa dữ liệu
sql
DELETE FROM users WHERE id = 123e4567-e89b-12d3-a456-426614174000;4. Hiểu cách Partition Key, Clustering Key ảnh hưởng đến truy vấn trong cassandra
Trong Cassandra, Partition Key và Clustering Key là hai thành phần cốt lõi của khóa chính (Primary Key) và ảnh hưởng trực tiếp đến cách dữ liệu được lưu trữ và truy xuất. Dưới đây là một số điểm chính:
4.1 Partition Key
Partition key là một hash để xác định node nào trong cluster sẽ lưu trữ dữ liệu. Điều này sẽ giúp phân phối đồng đều để giúp giảm tình trạng “hot partition” nếu một partition quá lớn hoặc có quá nhiều truy vấn.
Yêu cầu truy vấn: Khi thực hiện câu truy vấn, bắt buộc bạn phải chỉ định đầy đủ Partition Key. Nếu không, Cassandra sẽ phải quét toàn bộ cluster, dẫn đến hiệu năng rất kém.(Ví dụ có 10 Node thì sẽ cần quét cả 10 Node để tìm dữ liệu)
Ví dụ: Với bảng có định nghĩa PRIMARY KEY (user_id), truy vấn như SELECT * FROM table WHERE user_id = '123' sẽ được thực hiện nhanh chóng vì nó chỉ cần tìm đúng partition tương ứng từ việc hash Partition Key user_id.
Hiểu đơn giản hơn là Partition key sẽ xác định nơi ở của dữ liệu (Ví dụ: Việt Nam có rất nhiều tỉnh và thành phố, thanhlv ở Hoài Đức Hà Nội), đây gần như là điều kiện tối thiểu trong câu truy vấn WHERE để giúp tăng hiệu suất tìm kiếm và không gây quá tải.
Nếu không có Partition key thì sẽ cần tìm kiếm thanhlv ở trên toàn thế giới, một công việc rất vất vả.
4.2 Clustering Key
Sắp xếp dữ liệu trong partition: Sau khi dữ liệu được phân vùng bằng Partition Key, các giá trị trong cùng một partition sẽ được sắp xếp theo thứ tự của Clustering Key(Nếu có Clustering Key). Điều này cho phép bạn thực hiện các truy vấn theo phạm vi (range query) hoặc sắp xếp dữ liệu theo thứ tự đã định sẵn.
Tuy nhiên nếu không có Clustering Key và data có cùng một partition key thì data sẽ bị ghi đè vào dữ liệu cũ nếu đã tồn tại.
Truy vấn theo thứ tự: Khi truy vấn dữ liệu trong một partition, nếu bạn cần dữ liệu được sắp xếp (ví dụ theo thời gian hay theo giá trị tăng dần/giảm dần), bạn có thể sử dụng Clustering Key. Tuy nhiên, điều kiện trên Clustering Key phải tuân theo thứ tự được khai báo trong định nghĩa khóa chính.
Ví dụ: Với bảng định nghĩa PRIMARY KEY (user_id, timestamp), các truy vấn như SELECT * FROM table WHERE user_id = '123' AND timestamp > '2024-01-01' sẽ tận dụng thứ tự sắp xếp của timestamp, giúp lấy dữ liệu theo phạm vi một cách hiệu quả.
Hiểu đơn giản hơn thì Clustering Key sẽ giúp sắp xếp dữ liệu trong cùng một partition key.
5. Tóm tắt
- Cấu trúc dữ liệu trong Cassandra: Bao gồm Keyspace, Table, Partition Key, Clustering Key và Primary Key. Keyspace tương đương với database trong SQL, chứa các table và xác định cấu hình như Replication Factor và Replication Strategy.
- Primary Key: Bao gồm Simple Primary Key và Composite Primary Key. Simple Primary Key chỉ bao gồm một cột, trong khi Composite Primary Key bao gồm nhiều cột, với cột đầu tiên là Partition Key và các cột tiếp theo là Clustering Keys.
- Phân vùng và sao lưu dữ liệu: Cassandra sử dụng cơ chế partition để phân phối dữ liệu đến các node trong cluster dựa trên Partition Key. Replication Factor và Replication Strategy (SimpleStrategy và NetworkTopologyStrategy) xác định số lượng bản sao dữ liệu và cách chúng được phân phối.
- Cassandra Query Language (CQL): Ngôn ngữ truy vấn cho Cassandra, tương tự SQL nhưng được thiết kế riêng cho kiến trúc Cassandra. CQL hỗ trợ các định nghĩa schema nhưng không hỗ trợ các phép toán như join và hạn chế các phép toán tổng hợp.
- Ảnh hưởng của Partition Key và Clustering Key đến truy vấn: Partition Key giúp xác định node lưu trữ dữ liệu, cần được chỉ định trong truy vấn để tránh quét toàn bộ cluster. Clustering Key xác định thứ tự sắp xếp dữ liệu trong một partition, hỗ trợ truy vấn theo phạm vi và sắp xếp dữ liệu.
- Thiết kế lược đồ dữ liệu: Cần hiểu rõ về cấu trúc dữ liệu và cách thiết kế lược đồ trong Cassandra để tối ưu hóa hiệu suất và khả năng chịu lỗi của hệ thống.

Cập nhật lần cuối: