Appearance
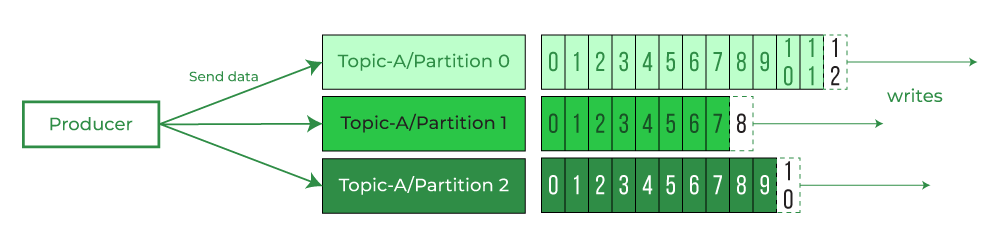
Kafka producer đã không còn Round Robin Partition với key null.
Chào mọi người,
Sau nhiều ngày được anh Lâm (Leader tại LINE) khuyến khích và động viên viết blog về công nghệ và tôi nhận thấy có khá nhiều bạn đã hiểu sai về Kafka trên phiên bản mới nhất. Điều này dẫn đến việc cấu hình partition và consumer bị sai khi sử dụng Kafka.
Vì vậy, bài viết này tôi sẽ thực hiện để đạt được hai mục tiêu:
- Viết một bài chia sẻ về công nghệ trên blog của LINE (Tuy nhiên, do thói quen viết blog, tôi vẫn sẽ đăng trên blog cá nhân trước).
- Giải thích rõ ràng về chủ đề của bài viết
Kafka producer đã không còn Round Robin Partitionvà cách Kafka hiện tại đang hoạt động.
Giá trị cấu hình linger.ms ảnh hưởng thế nào đến Latency(Độ trễ) và Throughput.
linger.mssẽ giúp chúng ta lựa chọn tối ưu Latency hoặc Throughput.
Latency thấp (gửi message nhanh chóng):
- Cài đặt
linger.msnhỏ (0-10ms) thì Producer sẽ gửi Record gần như ngay lập tức, tuy nhiên throughput sẽ không cao vì không có nhiều Record được gộp vào 1 batch. linger.msnhỏ sẽ làm tăng nhiều request đến máy chủ Kafka.
Throughput cao (Gửi nhiều message cùng lúc):
- Cài đặt
linger.mslớn ( 100ms -> N) điều này cho phép Producer đợi lâu hơn để gộp các Record thành một Batch để gửi, sẽ cải thiện hiệu suất nhưng tăng độ trễ linger.mssẽ giảm request gửi đến máy chủ Kafka
Từ phiên bản nhỏ hơn hoặc bằng v2.3.1 mặc định Kafka producer sẽ Round Robin Partition
Từ những phiên bản đầu tiên khi Kafka được Open Source đến phiên bản 2.3.1, mặc định Kafka producer khi gửi các Record có key là null sẽ thực hiện Round Robin Partition
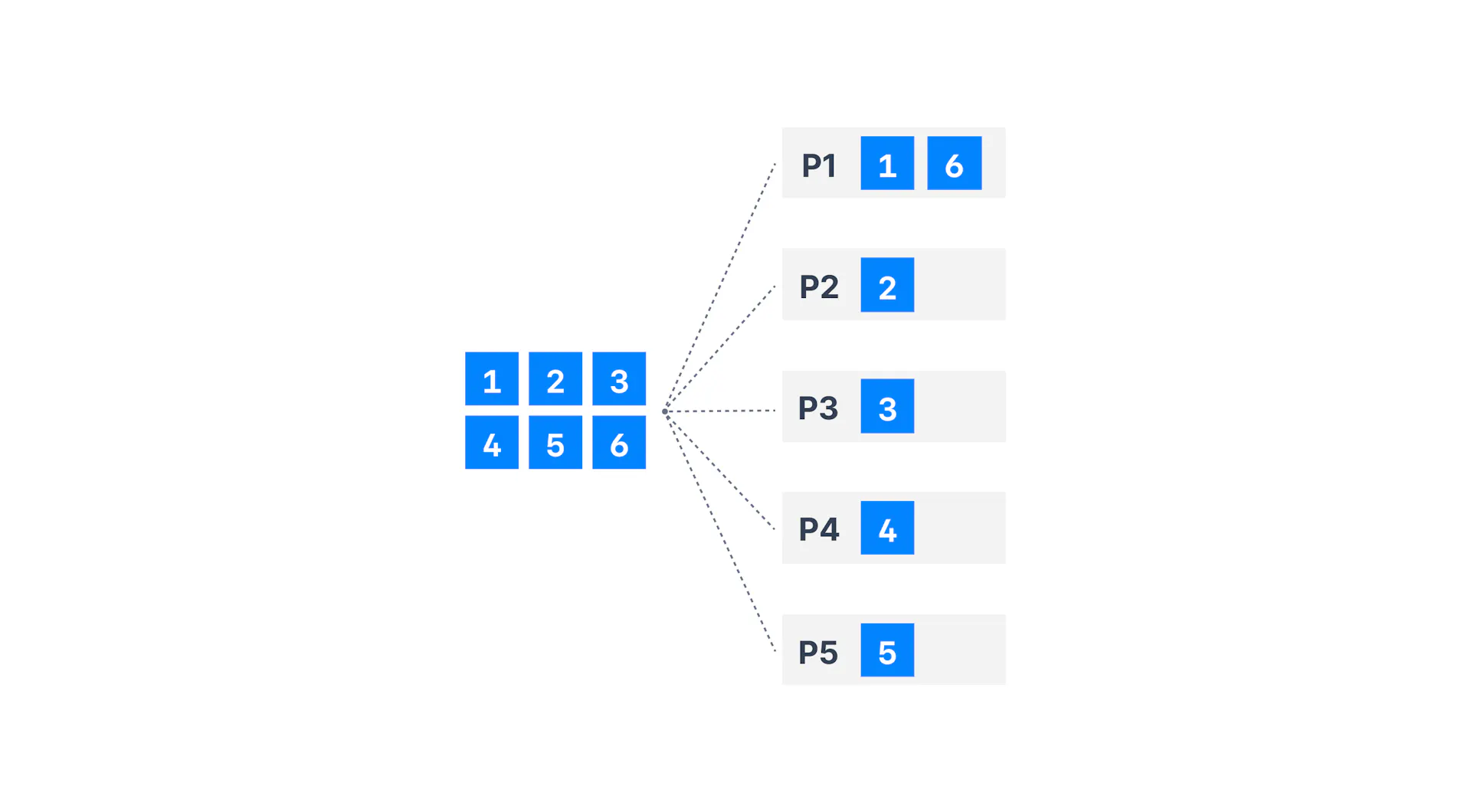
Dưới đây là đoạn code ở phiên bản 2.3.1 trên java, phiên bản cuối cùng Kafka Producer mặc định Round Robin Partition
java
package org.apache.kafka.clients.producer.internals;
.....
public class DefaultPartitioner implements Partitioner {
// Map ConcurrentMap để lưu trữ bộ đếm count cho từng topic
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap();
// Constructor mặc định
public DefaultPartitioner() {
}
// Phương thức cấu hình, hiện tại không làm gì
public void configure(Map<String, ?> configs) {
}
// Phương thức xác định phân vùng cho một bản ghi
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// Lấy danh sách các phân vùng cho chủ đề
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// Nếu không có khóa, sử dụng bộ đếm tuần tự để chọn phân vùng
if (keyBytes == null) {
int nextValue = this.nextValue(topic);
// lấy về danh sách partition khả dụng để ghi. (Không bao gồm các partition off)
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
// Nếu có phân vùng khả dụng, chọn một trong số chúng
if (availablePartitions.size() > 0) {
// Chuyển giá trị bộ đếm thành số dương và lấy phần dư khi chia cho số phân vùng khả dụng
// Ví dụ topic có 5 partition.
// part = 2107121300 % 5 ==> 0
// part = 2107121301 % 5 ==> 1
// part = 2107121302 % 5 ==> 2
// part = 2107121303 % 5 ==> 3
// part = 2107121304 % 5 ==> 4
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return ((PartitionInfo)availablePartitions.get(part)).partition();
} else {
// Nếu không có phân vùng khả dụng, chọn ngẫu nhiên trong tất cả các phân vùng
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// Nếu có khóa, sử dụng hàm băm Murmur2 để chọn phân vùng
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
// Phương thức lấy giá trị tiếp theo của bộ đếm cho một chủ đề
private int nextValue(String topic) {
// Lấy bộ đếm cho chủ đề từ bản đồ
AtomicInteger counter = (AtomicInteger)this.topicCounterMap.get(topic);
// Nếu bộ đếm chưa tồn tại, khởi tạo nó với giá trị ngẫu nhiên
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = (AtomicInteger)this.topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
// Tăng giá trị bộ đếm và trả về giá trị trước khi tăng
return counter.getAndIncrement();
}
// Phương thức đóng, hiện tại không làm gì
public void close() {
}
}Và tất nhiên danh sách ở trong availablePartitions không được sort từ 0 - N vì vậy đôi khi bạn thấy Record 1 đến Partition 1 nhưng Record 2 đến Partition 3. Tuy nhiên, bạn có thể yên tâm rằng nó vẫn là Round Robin Partition
2.4.0 đến 3.2.3 Kafka producer stickyPartition
Nói lại một chút về Kafka producer Round Robin Partition và vấn đề gặp phải
Round Robin Partitionlà một tính năng rất hay và hữu ích, giúp chia tải cân bằng giữa các Partition để các Consumer có thể chia sẻ tải và xử lý dữ liệu- Tuy nhiên, trong trường hợp
linger.msđược bật,throughput thấpsẽ làm tăng độ trễ khi push dữ liệu lên Kafka, bởi vì không có đủ Record để lấp đầy Batch theo cấu hìnhbatch.size producer Round Robin Partitiongiúp phân phối các Record đều giữa các partition, nhưng nó cũng dẫn đến việc tạo ra nhiều Batch có kích thước nhỏ, đặc biệt khi throughput thấp.- Điều này gây ra vấn đề vì các Record cùng một partition sẽ được đưa vào cùng một batch để gửi. Do đó, khi throughput thấp, cần chờ đến khi đạt giá trị
linger.msđể gửi dữ liệu.
- Điều này gây ra vấn đề vì các Record cùng một partition sẽ được đưa vào cùng một batch để gửi. Do đó, khi throughput thấp, cần chờ đến khi đạt giá trị
- Nói một cách đơn giản, khi cấu hình
linger.ms,Round Robin Partitionsẽ tạo ra nhiều Batch nhỏ. Nếu throughput thấp, các batch sẽ không được làm đầy theo cấu hìnhbatch.size, dẫn đến việc tăng độ trễ.
Giả sử bạn có 3 partitions (P0, P1, P2) và bạn gửi 9 records sau mỗi 5ms (R1, R2, ..., R9) mà không chỉ định partition hoặc key. Default partitioner sẽ phân phối các records theo vòng tròn (round-robin):
5ms : R1 -> P0
10ms : R2 -> P1
15ms : R3 -> P2
20ms : R4 -> P0
25ms : R5 -> P1
30s : R6 -> P2
35ms : R7 -> P0
40ms : R8 -> P1
45ms : R9 -> P2
Với linger.ms=0, mỗi record sẽ được gửi ngay lập tức với tổng cộng 9 batch, mỗi batch chứa một record:
5ms : Batch 1: R1 (P0) ==> send request
10ms :Batch 2: R2 (P1) ==> send request
15ms :Batch 3: R3 (P2) ==> send request
20ms :Batch 4: R4 (P0) ==> send request
25ms :Batch 5: R5 (P1) ==> send request
30s : Batch 6: R6 (P2) ==> send request
35ms :Batch 7: R7 (P0) ==> send request
40ms :Batch 8: R8 (P1) ==> send request
45ms :Batch 9: R9 (P2) ==> send request- Trong trường hợp cấu hình
linger.ms > 0ví dụ là 50ms =linger.ms=505ms : R1 -> P0 -> Batch 1 10ms : R2 -> P1 -> Batch 2 15ms : R3 -> P2 -> Batch 3 20ms : R4 -> P0 -> Batch 1 25ms : R5 -> P1 -> Batch 2 30ms : R6 -> P2 -> Batch 3 35ms : R7 -> P0 -> Batch 1 40ms : R8 -> P1 -> Batch 2 45ms : R9 -> P2 -> Batch 2 50ms -> bắt đầu gửi data Batch 1 Batch 1: R1 (P0), R4 (P0), R7 (P0) 55ms -> bắt đầu gửi data Batch 2 Batch 2: R2 (P1), R5 (P1), R8 (P1) 60ms -> bắt đầu gửi data Batch 3 Batch 3: R3 (P2), R6 (P2), R9 (P2) Tổng cộng 3 batch, mỗi batch chứa một 3 record nhưng sau 50ms(Tính từ khi tạo batch) thì mới bắt đầu gửi dữ liệu lên Kafka- Nếu throughput thấp(Ít dữ liệu cần gửi lên) thì sẽ gây ra độ trễ vì không có đủ
batch.sizeđể bắt đầu gửi lênBrokernên sẽ cần chờ đủlinger.msđể gửi. Ví dụlinger.ms=50
5ms : R1 -> P0 -> Batch 1 10ms : R2 -> P1 -> Batch 2 15ms : R3 -> P2 -> Batch 3 50ms -> bắt đầu gửi data Batch 1 Batch 1: R1 (P0) 55ms -> bắt đầu gửi data Batch 2 Batch 2: R2 (P1) 60ms -> bắt đầu gửi data Batch 3 Batch 3: R3 (P2) Tổng cộng 3 batch, mỗi batch chứa một 1 record nhưng sau 50ms(Tính từ khi tạo batch) thì mới bắt đầu gửi dữ liệu lên Kafka - Nếu throughput thấp(Ít dữ liệu cần gửi lên) thì sẽ gây ra độ trễ vì không có đủ
Kafka producer stickyPartition(2.4.0 >= N <=3.2.3)
- https://issues.apache.org/jira/browse/KAFKA-8601
- PR : https://github.com/apache/kafka/pull/6997/files , https://github.com/apache/kafka/pull/7199/files Từ phiên bản 2.4.0 đến 3.2.3 (2.4.0 >= N <=3.2.3) Kafka Producer thay vì mặc định Round Robin Partition khi key null thì sẽ chuyển sang thuật toán
stickyPartitionkhi key null.
Với sticky Partition Cache thì partition sẽ được tính theo Batch, tất cả các Record có key == null trong cùng BATCH của cùng 1 topic sẽ được gửi lên cùng nhau sẽ trên cùng một partition. Với sticky sẽ làm tăng tỉ lệ lấp đầy batch.size. 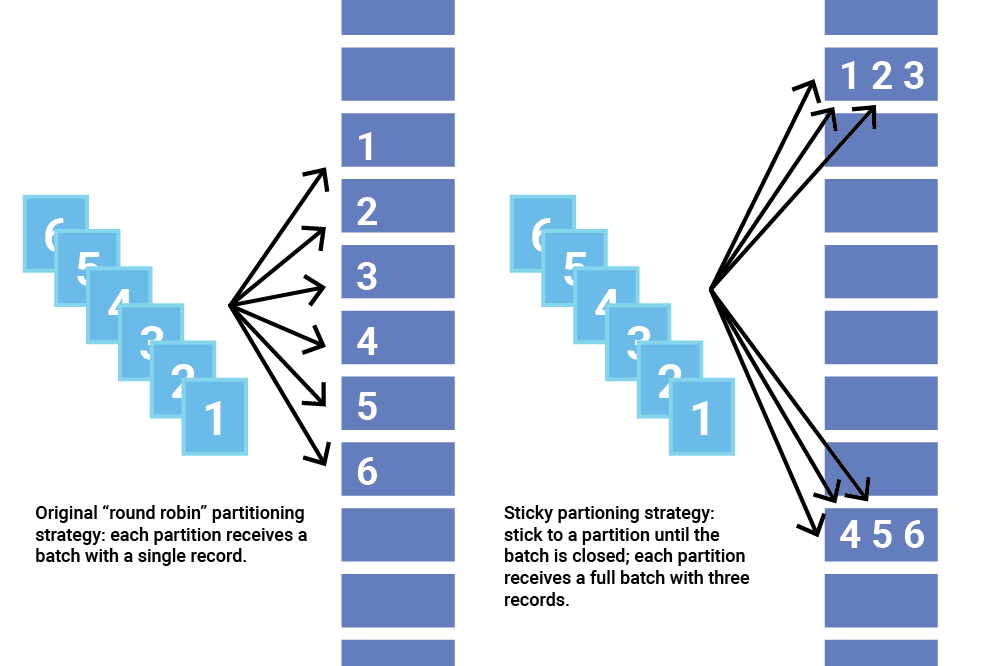
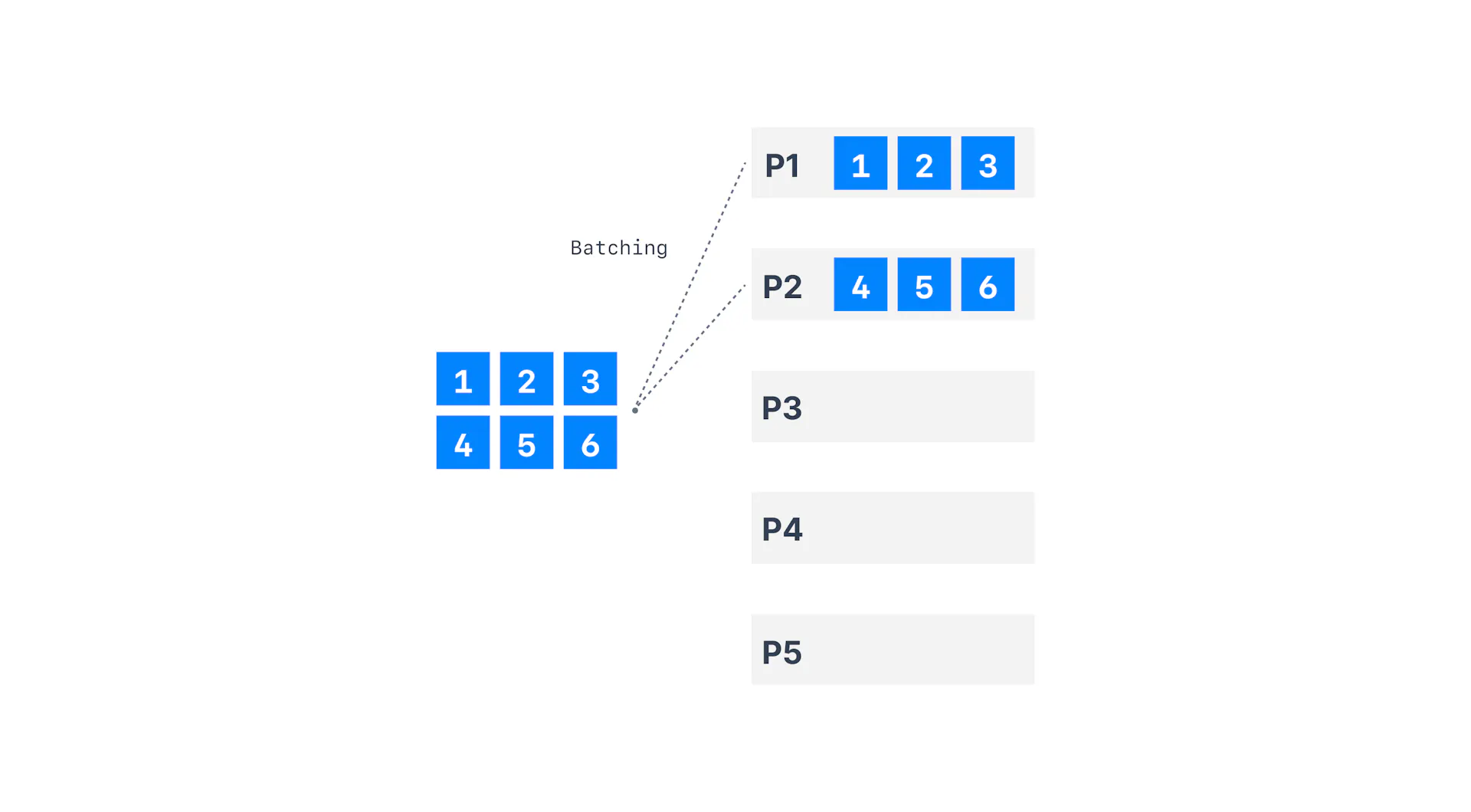
Ví dụ với linger.ms=50 và batch.size đủ cho khoảng 3 Record. Khi tạo Batch mới thì Kafka Producer sẽ ngẫu nhiên partition.
5ms : R1 -> Tạo Batch 1 và random partition -> P0
10ms : R2 -> Batch 1
15ms : R3 -> Batch 1 -> lấp đầy BatchSie
16ms -> bắt đầu gửi data Batch 1
Batch 1: R1 (P0), R2 (P0), R3 (P0),
Tổng cộng batch 1 chứa 3 record và được gửi ngay sau khi đầy batch.sizejava
package org.apache.kafka.clients.producer.internals;
...
public class DefaultPartitioner implements Partitioner {
private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();
public DefaultPartitioner() {
}
public void configure(Map<String, ?> configs) {
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return this.partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) {
return keyBytes == null
// nếu key null sử dụng stickyPartitionCache để lấy về partition
? this.stickyPartitionCache.partition(topic, cluster)
// nếu key không null, tính hash của key và chia lấy dư cho numPartitions,
// trong case này nếu cùng một key thì sẽ luôn trả về cùng một partition
: Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
public void close() {
}
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
// Mỗi khi tạo mới Batch cho topic sẽ thực hiện tính toán lại partition cho batch mới.
this.stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
}
package org.apache.kafka.clients.producer.internals;
...
// Lớp chịu trách nhiệm quản lý sticky partitioning cho các topic trong Kafka.
public class StickyPartitionCache {
// Cache để lưu trữ chỉ số partition hiện tại cho mỗi topic.
private final ConcurrentMap<String, Integer> indexCache = new ConcurrentHashMap<>();
// Constructor: Khởi tạo một đối tượng StickyPartitionCache mới.
public StickyPartitionCache() {
}
// Phương thức để lấy partition hiện tại cho một topic cụ thể.
// Nếu partition đã được cache, trả về nó; nếu không, tính toán partition tiếp theo.
// Đây là method được gọi bởi method partition trong class DefaultPartitioner để lấy về partititon
public int partition(String topic, Cluster cluster) {
Integer part = this.indexCache.get(topic);
return part == null ? this.nextPartition(topic, cluster, -1) : part;
}
// Phương thức xác định partition tiếp theo cho một topic cụ thể.
// Nếu không có partition khả dụng hoặc partition giống như trước, chọn một partition ngẫu nhiên.
public int nextPartition(String topic, Cluster cluster, int prevPartition) {
// Lấy danh sách tất cả các partition cho topic.
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
Integer oldPart = this.indexCache.get(topic);
Integer newPart = oldPart;
// Nếu partition cũ(Partition hiện tại trong cache) không phải là partition trước đó, trả về partition cũ từ cache.
if (oldPart != null && oldPart != prevPartition) {
return this.indexCache.get(topic);
} else {
// Lấy danh sách các partition khả dụng cho topic.(Không bao gồm các partition off)
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
// Nếu không có partition khả dụng, chọn một partition ngẫu nhiên.
if (availablePartitions.size() < 1) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = random % partitions.size();
}
// Nếu chỉ có một partition khả dụng, sử dụng partition đó.
else if (availablePartitions.size() == 1) {
newPart = availablePartitions.get(0).partition();
}
// Nếu có nhiều partition khả dụng, chọn một partition ngẫu nhiên khác với partition cũ.
else {
while(newPart == null || newPart.equals(oldPart)) {
int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = availablePartitions.get(random % availablePartitions.size()).partition();
}
}
// Cập nhật cache với partition mới.
if (oldPart == null) {
this.indexCache.putIfAbsent(topic, newPart);
} else {
this.indexCache.replace(topic, prevPartition, newPart);
}
// Trả về partition mới từ cache.
return this.indexCache.get(topic);
}
}
}Nhìn vào đoạn code ở phía trên bạn có thể thấy, Mỗi khi bắt đầu một batch mới cho topic thì Kafka sẽ tính toán ngẫu nhiên lại Partition cho key null.
REF: https://cwiki.apache.org/confluence/display/KAFKA/KIP-480%3A+Sticky+Partitioner , https://issues.apache.org/jira/browse/KAFKA-14156
3.3.0 đến mới nhất(3.8.0 là phiên bản hiện tại viết bài này ) Strictly Uniform Sticky Partitioner'
REF: https://cwiki.apache.org/confluence/display/KAFKA/KIP-794%3A+Strictly+Uniform+Sticky+Partitioner
Các vấn đề gặp phải của Kafka producer stickyPartition(2.4.0 >= N <=3.2.3)
- Vấn đề của stickyPartition sẽ phân phối nhiều Record đến các máy chủ Kafka slow(Chậm). Nếu có 1 máy chủ Kafka chậm sẽ khiến Batch gửi đến Partition trên máy chủ đó sẽ lớn hơn, vì nó chậm nên lưu lâu hơn vì vậy nó ảnh hướng đến hiệu suất hệ thống.
- Vấn đề này xảy ra vì
stickyPartitionđược điều khiển bởi việc tạo batch mới, tuy nhiêndraincác Batch cho máy chủ chậm sẽ lâu hơn vì máy chủ chưa sẵn sàng nhận các Request mới, vì vậy Record tiếp tục được push vào batch đang chờ gửi.
java
package org.apache.kafka.clients.producer.internals;
...
public class Sender implements Runnable {
private long sendProducerData(long now) {
Cluster cluster = metadata.fetch();
// lấy về danh sách node có batch đủ điều kiện để gửi (đầy batch hoặc đủ lingerMs)
// get the list of partitions with data ready to send
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// if there are any partitions whose leaders are not known yet, force metadata update
if (!result.unknownLeaderTopics.isEmpty()) {
// The set of topics with unknown leader contains topics with leader election pending as well as
// topics which may have expired. Add the topic again to metadata to ensure it is included
// and request metadata update, since there are messages to send to the topic.
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
result.unknownLeaderTopics);
this.metadata.requestUpdate();
}
// Xóa các Node không sẵn sàng để gửi
// remove any nodes we aren't ready to send to
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while(iter.hasNext()){
Node node = iter.next();
// kiểm tra các node là sẵn sàng nhận request
if (!this.client.ready(node, now)) {
// Nếu node không sẵn sàng, xóa nó khỏi danh sách. Các node slow có tỉ lệ sẵn sàng thấp nên hay bị xóa.
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
// create produce requests trên các node sẵn sàng.
// drain sẽ thực hiện Rút các data trong batch ra
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
...
// thực hiện gửi Batch và xóa batch sau khi gửi thành công.
sendProduceRequests(batches, now);
}Strictly Uniform Sticky Partitioner (3.3.0 > N)
- Từ phiên bản 3.3.0 đến hiện tại Kafka producer vẫn chọn ngẫu nhiên partition, tuy nhiên thời điểm để chọn lại partition đã thay đổi.
- Tại phiên bản này Kafka producer sẽ sử dụng config
batch.sizeđể xác định thời điểm lựa chọn lại partition và có một bộ cân bằng tải để hạn chế push nhiều Record vào Partition trên node slower trong trường hợp Throughput đang cao. - Về cơ bản từ phiên bản 3.3.0 vấn đề tối ưu đã khá ổn và ổn định cho nhiều case.
- Mỗi khi thêm một Record mới, kafka sẽ tính toán Record tốn bao nhiêu byte( Metadata +data ) sau đó cộng vào một biến count,
- Sau đó thay vì ở phiên bản
2.4.0 đến 3.2.3sẽ ngẫu nhiên lựa chọn lại partition mỗi lần tạo batch thì từphiên bản 3.3.0sẽ thực kiểm tra khi biến count lớn hơnbatch.sizesẽ bắt đầu thực hiện chọn lại partition.
- Sau đó thay vì ở phiên bản
Code lib Kafka, thực tế trong BuiltInPartitioner sẽ có nhiều method khác nữa, tôi đã bỏ các method khác đi để chỉ tập trung vào nextPartition và updatePartitionInfo
java
package org.apache.kafka.clients.producer.internals;
import ....
public class BuiltInPartitioner {
private final Logger log;
private final String topic;
private final int stickybatch.size;
private volatile PartitionLoadStats partitionLoadStats = null;
private final AtomicReference<StickyPartitionInfo> stickyPartitionInfo
= new AtomicReference();
public static volatile Supplier<Integer> mockRandom = null;
public BuiltInPartitioner(LogContext logContext, String topic, int stickybatch.size) {
this.log = logContext.logger(BuiltInPartitioner.class);
this.topic = topic;
if (stickybatch.size < 1) {
throw new IllegalArgumentException("stickybatch.size must be >= 1 but got " + stickybatch.size);
} else {
// được config bởi "batch.size".
// Giá trị mặc định của "batch.size" là 16384
// (https://github.com/apache/kafka/blob/4a485ddb71c844acc8bf241feda1fcbffc5ce9be/clients/src/main/java/org/apache/kafka/clients/producer/ProducerConfig.java#L384)
this.stickybatch.size = stickybatch.size;
}
}
private int nextPartition(Cluster cluster) {
// mockRandom là test của dev, có thể bỏ qua
// response của line code này là 1 số ngẫu nhiên
int random = mockRandom != null ? (Integer)mockRandom.get() : Utils.toPositive(ThreadLocalRandom.current().nextInt());
PartitionLoadStats partitionLoadStats = this.partitionLoadStats;
int partition;
//nếu partitionLoadStats == null sẽ lấy ngẫu nhiên giống 2.4.0 đến 3.2.3
if (partitionLoadStats == null) {
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(this.topic);
if (!availablePartitions.isEmpty()) {
// từ số random, chia lấy dư cho số lượng availablePartitions
partition = ((PartitionInfo)availablePartitions.get(random % availablePartitions.size())).partition();
} else {
// nếu không có availablePartitions, lấy ngẫu nhiên ở tất cho partition
List<PartitionInfo> partitions = cluster.partitionsForTopic(this.topic);
partition = random % partitions.size();
}
} else {
// tính toán dựa trên lượng tải của partition
// Nếu lượng tải quá lớn cùng một thời gian ngắn, partitionLoadStats sẽ not null và sử dụng partitionLoadStats để tính toán partition mới
// Sau 1 khoản thời gian lượng tải hết lớn, partitionLoadStats sẽ null và sử dụng random
//
assert partitionLoadStats.length > 0;
int[] cumulativeFrequencyTable = partitionLoadStats.cumulativeFrequencyTable;
// tạo trọng số ngẫu nhiên bằng cách lấy dư của random / cho giá trị cuối cùng trong bảng tần suất tích lũy.
int weightedRandom = random % cumulativeFrequencyTable[partitionLoadStats.length - 1];
// Sử dụng tìm kiếm nhị phân để tìm chỉ số của partition tương ứng với số ngẫu nhiên có trọng số trong bảng tần suất tích lũy.
// nếu không tìm thấy, result sẽ trả về vị trí giá trị nên được thêm.
int searchResult = Arrays.binarySearch(cumulativeFrequencyTable, 0, partitionLoadStats.length, weightedRandom);
int partitionIndex = Math.abs(searchResult + 1);
assert partitionIndex < partitionLoadStats.length;
partition = partitionLoadStats.partitionIds[partitionIndex];
}
this.log.trace("Switching to partition {} in topic {}", partition, this.topic);
return partition;
}
void updatePartitionInfo(StickyPartitionInfo partitionInfo, int appendedBytes, Cluster cluster, boolean enableSwitch) {
if (partitionInfo != null) {
assert partitionInfo == this.stickyPartitionInfo.get();
int producedBytes = partitionInfo.producedBytes.addAndGet(appendedBytes);
if (producedBytes >= this.stickybatch.size * 2) {
this.log.trace("Produced {} bytes, exceeding twice the batch size of {} bytes, with switching set to {}", new Object[]{producedBytes, this.stickybatch.size, enableSwitch});
}
if (producedBytes >= this.stickybatch.size && enableSwitch || producedBytes >= this.stickybatch.size * 2) {
// Nếu tổng số producedBytes hiện tại lớn hớn config stickybatch.size và enableSwitch = true hoặc producedBytes lớn hơn gấp 2 lần stickybatch.size thì sẽ force update
StickyPartitionInfo newPartitionInfo = new StickyPartitionInfo(this.nextPartition(cluster));
this.stickyPartitionInfo.set(newPartitionInfo);
}
}
}
private final static class PartitionLoadStats {
// load tải table, có size array tối đa = số lượng partition
public final int[] cumulativeFrequencyTable;
// danh sach partition id cua topic
public final int[] partitionIds;
public final int length;
public PartitionLoadStats(int[] cumulativeFrequencyTable, int[] partitionIds, int length) {
assert cumulativeFrequencyTable.length == partitionIds.length;
assert length <= cumulativeFrequencyTable.length;
this.cumulativeFrequencyTable = cumulativeFrequencyTable;
this.partitionIds = partitionIds;
this.length = length;
}
}
}Các thành phần khác
Nhìn đoạn code ở phía trên cũng đã rất phức tạp 😄 Tuy nhiên chúng ta còn rất nhiều logic khác nữa, tôi sẽ kể ra 1 số logic đặc biệt cần lưu ý cho mọi người.
Logic tính toán số lượng Bytes cho mỗi Record
- Method static thực hiện điều này chính là
DefaultRecordBatch.estimatebatch.sizeUpperBound(key, value, headers);
java
static int estimatebatch.sizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) {
// RECORD_BATCH_OVERHEAD = 61 ;
return RECORD_BATCH_OVERHEAD + DefaultRecord.recordSizeUpperBound(key, value, headers);
}
static int recordSizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) {
int keySize = key == null ? -1 : key.remaining();
int valueSize = value == null ? -1 : value.remaining();
// MAX_RECORD_OVERHEAD = 21
return MAX_RECORD_OVERHEAD + sizeOf(keySize, valueSize, headers);
}
private static int sizeOf(int keySize, int valueSize, Header[] headers) {
int size = 0;
if (keySize < 0)
size += NULL_VARINT_SIZE_BYTES;
else
size += ByteUtils.sizeOfVarint(keySize) + keySize;
if (valueSize < 0)
size += NULL_VARINT_SIZE_BYTES;
else
size += ByteUtils.sizeOfVarint(valueSize) + valueSize;
if (headers == null)
throw new IllegalArgumentException("Headers cannot be null");
size += ByteUtils.sizeOfVarint(headers.length);
for (Header header : headers) {
String headerKey = header.key();
if (headerKey == null)
throw new IllegalArgumentException("Invalid null header key found in headers");
int headerKeySize = Utils.utf8Length(headerKey);
size += ByteUtils.sizeOfVarint(headerKeySize) + headerKeySize;
byte[] headerValue = header.value();
if (headerValue == null) {
size += NULL_VARINT_SIZE_BYTES;
} else {
size += ByteUtils.sizeOfVarint(headerValue.length) + headerValue.length;
}
}
return size;
}Nhìn có vẻ phức tạp nhưng bạn có thể hiểu đơn giản như này.
Size = RECORD_BATCH_OVERHEAD + MAX_RECORD_OVERHEAD + sizeOf(keySize, valueSize, headers)
= 61 + 21 + sizeOf(keySize, valueSize, headers)
Trường hợp key null và value rỗng(0) và header empty
= 61 + 21 + NULL_VARINT_SIZE_BYTES(Key) + NULL_VARINT_SIZE_BYTES(Value)+NULL_VARINT_SIZE_BYTES(headers)
= 61 + 21 + 1 + 1 + 1 = 85
Trường hợp có dữ liệu = 61 + 21 + keyByte + valueByte + headersByteVì vậy ít nhất mỗi Record sẽ có size bytes được tăng thêm là 85
Logic tính toán cumulativeFrequencyTable
cumulativeFrequencyTablelà một table sử dụng để thống kê tải (load) partition cho từng topic, nó được sử dụng để xác định partition mới khi thực hiện xác định lại partition.cumulativeFrequencyTablesẽ giúp chúng ta lựa chọn partition mới để chia tải gần như cân bằng giữa các partition.
java
public class CalPartitionLoad {
public static void main(String[] args) {
Integer[] queueSizes = {8, 3, 14, 8, 5};
run(queueSizes);
// Output: [7, 19, 20, 27, 37]
}
public static void run(Integer[] queueSizes){
// queueSizes length = max partition, queueSizes là số lượng batch data đang cho gui den partition
/**
* ví dụ : Integer[] queueSizes = {8, 3, 14};
* Có 3 partiotn là 0,1,2
* partiton 0 có 8 batch đang chờ gửi
* partiton 1 có 3 batch đang chờ gửi
* partiton 14 có 8 batch đang chờ gửi
*/
// lấy về số lớn nhất + 1
int maxSizePlus1 = queueSizes[0];
// trong thực tế, length là tham số truyền vào biểu diễn số lượng partition đang có leader và có thể gửi data
int length = queueSizes.length;
boolean allEqual = true;
for (int i = 1; i < length; i++) {
if (queueSizes[i] != maxSizePlus1)
allEqual = false;
if (queueSizes[i] > maxSizePlus1)
maxSizePlus1 = queueSizes[i];
}
++maxSizePlus1;
//
if (allEqual) {
System.out.println("allEqual && queueSizes.length == queueSizes.length");
return;
}
// mỗi phần tử tiếp theo được tính bằng cách sử dụng giá trị lớn nhất và cộng dồn các phần tử trước đó.
//Với queueSizes = {8, 3, 14} và maxSizePlus1 = 15:
//queueSizes[0] = 15 - 8 = 7
//queueSizes[1] = 15 - 3 + 7 = 19
//queueSizes[2] = 15 - 14 + 19 = 20
//Kết quả cuối cùng: queueSizes = {7, 19, 20}.
queueSizes[0] = maxSizePlus1 - queueSizes[0];
for (int i = 1; i < length; i++) {
queueSizes[i] = maxSizePlus1 - queueSizes[i] + queueSizes[i - 1];
}
System.out.println("Output: "+ Arrays.stream(queueSizes).toList());
}
}Các cấu hình mới
partitioner.adaptive.partitioning.enablemặc định làtrue. Nếu làtrue, thì sẽ sử dụng bộ cân bằng tải để điều chỉnh phù hợp theo hiệu suất của các node, gửi ít record đến node chậm hơn- Nếu là
false, các partition sẽ được chọn ngẫu nhiên.
- Nếu là
partitioner.availability.timeout.msmặc định là0. Nếu giá trị lớn hơn0vàpartitioner.adaptive.partitioning.enablelàtrue, và producer không thể gửi request đến partition trong khoảng thời gianmsđịnh trước, thì partition đó sẽ được đánh dấu là bỏ qua.partitioner.ignore.keysmặc định làfalse. Nếu làfalsevàcó key, thì sẽ sử dụng key để tính toán partition. Nếu làtruevàcó key, thì sẽ bỏ qua logic sử dụng key để tính toán partition và sử dụng logic của Strictly Uniform Sticky Partitioner.
Thử nghiệm các trường hợp tạo ra vấn đề
Thông tin thử nghiệm:
- 4 node
- 10 partition
- image docker
confluentinc/cp-kafka:7.4.4( kafka server version: 3.5.0 ) - Hardware Overview:
Model Name: MacBook Pro
Model Identifier: MacBookPro18,1
Chip: Apple M1 Pro
Total Number of Cores: 10 (8 performance and 2 efficiency)
Memory: 16 GB
System Firmware Version: 8422.141.2
OS Loader Version: 8422.141.2Topic
kafka-topics --bootstrap-server kafka1:19092 --create --if-not-exists --topic topic-rep-1-partition-10 --replication-factor 1 --partitions 10- Node Info (Xem full tại đây)
Node 1:
- 3 cpu
- max 3g RAM
Node 2:
- 3 cpu
- max 3g RAM
Node 3:
- 3 cpu
- max 3g RAM
Node 4:
- 3 cpu
- max 3g RAM- Lệnh xem log số lượng Record được gửi thành công lên server cho 1 request gửi (Tương ứng với Số lượng record trong batch sử dụng để gửi)
grep -n "Set last ack'd sequence number for topic-partition topic-rep-1-partition-10-" kafka_client.logKafka Producer Partitioning (phiên bản <= 2.3.1):
- Phiên bản sử dụng : kafka-clients-2.3.1
1. Case test: Tái hiện Latency cao do throughput thấp
- Code chạy
java
@Slf4j
public class KeyNullLoopDelay {
@SneakyThrows
public static void main(String[] args) throws IOException {
System.setProperty("org.slf4j.simpleLogger.defaultLogLevel", "ALL");
final var props = new Properties();
props.setProperty(ProducerConfig.CLIENT_ID_CONFIG, "java-producer-producerRecordPartition-KeyNotNull");
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29091,localhost:29092,localhost:29093,localhost:29094");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "5000");
// 15s
props.setProperty(ProducerConfig.LINGER_MS_CONFIG, "15000");
try (var producer = new KafkaProducer<Object, String>(props)) {
while (true) {
final var messageProducerRecord = new ProducerRecord<>(
"topic-rep-1-partition-10", //topic name
// 36 byte
UUID.randomUUID().toString() // value
);
Integer numberSend = 113;
for (int i = 1; i <= numberSend; i++) {
producer.send(messageProducerRecord);
}
// 30s
Thread.sleep(30000);
}
}
}
}- Giải thích cách code hoạt động:
- Sẽ gửi 113 Record lến Kafka server, đối với
BATCH_SIZE_CONFIG = 5000nếu push vào 1 Batch duy nhất sẽ đầy batch.size và gửi lên Kafka server. Tuy nhiên bởi vì Round Robin trên 10 Partition nên có 10 Batch và mỗi Batch có 11 đến 12 Record nên chưa đủ batch.size. - Bởi vì chưa chưa đủ batch.size nên cần chờ đến thời gian của
LINGER_MS_CONFIGmới bắt đầu gửi Batch vì vậy nó tạo ra Latency cao vì throughput thấp
- Sẽ gửi 113 Record lến Kafka server, đối với
Kafka Producer Sticky Partitioning (phiên bản 2.4.0 đến 3.2.3):
- Phiên bản sử dụng : kafka-clients-3.2.3
1. Case test: Tái hiện việc phân phối nhiều Record vào Node Slower
- Node Info (Xem full tại đây)
Node 1:
- 0.2 cpu
- max 3g RAM
Node 2:
- 3 cpu
- max 3g RAM
Node 3:
- 0.3 cpu
- max 3g RAM
Node 4:
- 3 cpu
- max 3g RAM- Sẽ có node 1 và 3 là slower.
java
@Slf4j
public class KeyNull {
@SneakyThrows
public static void main(String[] args) throws IOException {
System.setProperty("org.slf4j.simpleLogger.defaultLogLevel", "ALL");
final var props = new Properties();
props.setProperty(ProducerConfig.CLIENT_ID_CONFIG, "java-producer-producerRecordPartition-KeyNotNull");
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29091,localhost:29092,localhost:29093,localhost:29094");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "5000");
try (var producer = new KafkaProducer<Object, String>(props)) {
final var messageProducerRecord = new ProducerRecord<>(
"topic-rep-1-partition-10", //topic name
// 36 byte
UUID.randomUUID().toString() // value
);
Integer numberSend = 100_000;
for (int i = 1; i <= numberSend; i++) {
producer.send(messageProducerRecord);
}
}
}
}- Kết quả
- Khi nhìn vào kết quả ở log, bạn sẽ thấy các Partition của Node 1 và 3 sẽ luôn có nhiều Record hơn. (1,3,4,7,9) và sẽ có nhiều Batch của các partition đó được gửi cuối cùng
Kafka Producer Partitioning (phiên bản 3.3.0 trở lên):
- Phiên bản sử dụng : kafka-clients-3.8.0
- Code và data tương tự ví dụ
Case test: Tái hiện việc phân phối nhiều Record vào Node Slower - Kết quả
- Khi nhìn vào kết quả ở log, bạn sẽ thấy các Partition của Node 1 và 3 sẽ cón ít record Record hơn. (1,3,5,7,8)
tổng kết
Kafka Producer Partitioning (phiên bản <= 2.3.1):
Phiên bản <= 2.3.1: Kafka Producer sử dụng Round Robin Partitioning, chia đều record giữa các partition. Tuy nhiên, linger.ms lớn có thể tạo ra nhiều batch nhỏ, gây ra độ trễ khi throughput thấp.
Kafka Producer Sticky Partitioning (phiên bản 2.4.0 đến 3.2.3):
Phiên bản 2.4.0 - 3.2.3: Chuyển từ Round Robin sang stickyPartition. Các record trong một batch có key null sẽ được gửi cùng một partition, giúp lấp đầy batch.size tốt hơn. Tuy nhiên, trong Sticky Partitionin nếu có các node chậm thì các record sẽ được gửi đến các node chậm nhiều hơn, gây ra vấn đề về hiệu suất cho toàn Cluster khi có node hoạt động chậm
Kafka Producer Strictly Uniform Sticky Partitioner (phiên bản 3.3.0 trở lên):
Phiên bản >= 3.3.0: Sử dụng Strictly Uniform Sticky Partitioner, điều chỉnh phân phối partition dựa trên batch.size và tránh gửi quá nhiều record đến các node chậm, giúp tối ưu hiệu suất hệ thống.
2 logic với 2 trường hợp khi tải cao hoặc thấp.
1. Lựa chọn ngẫu nhiên
Trong trường hợp tải không cao, partition thiếp theo sẽ được chọn ngẫu nhiên.
2. Chọn partition dựa theo Cumulative Frequency Table:
Đây là bảng thống kê tải của partition, giúp cân bằng việc phân phối các record vào partition dựa trên trọng số của từng partition.
Kích thước tối thiểu mỗi record
Kích thước mỗi record tối thiểu là 85 bytes, bao gồm metadata, key, value và headers. Các phiên bản mới hơn của Kafka cải thiện hiệu quả việc chọn partition bằng cách điều chỉnh khi nào partition được chọn lại dựa trên tải và kích thước batch.

Cập nhật lần cuối: