Appearance
Tìm hiểu lịch sử và mục đích của kafka
Trong bài viết này, chúng ta sẽ cùng nhau bước vào hành trình khám phá Kafka, một công nghệ đã và đang làm thay đổi cách thức xử lý dữ liệu trong thế giới số.
Từ những đặc điểm đến những mục tiêu chiến lược mà Kafka hướng đến, chúng ta sẽ cùng nhau tìm hiểu sâu hơn về công nghệ này, làm sáng tỏ những ưu điểm và lý do tại sao Kafka lại trở thành một phần không thể thiếu trong hệ sinh thái dữ liệu hiện đại.
Kafka là gì ?
- Apache Kafka là một Event stream platform được phát triển bởi LinkedIn và quyên góp cho apache và phát hành thành mã nguồn mở (Open-source) vào năm 2011.
- Apache Kafka được viết bằng
ScalavàJava. Dự án này nhằm mục đích cung cấp một nền tảng có khả năng xử lý dữ liệu với lượng thông tin lớn, độ trễ thấp, phù hợp cho việc xử lý dữ liệureal-time - Ở high level, Kafka là một hệ thống phân tán servers và clients. Servers được gọi là brokers và client được chia làm 2 là record producers sending và consumer clients read records
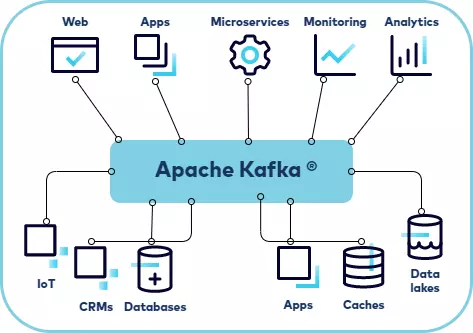
- Kafka cung cấp đầy đủ mọi thứ để chúng ta có thể triển khai event Streaming application một cách đầy đủ
Vì sao là kafka ?
Distributed System(Hệ thống phân tán): Apache Kafka là một hệ thống phân tán được thiết kế chạy trên nhiều máy chủ, đảm bảo tính sẵn sàng cao và khả năng chịu lỗi.
Publish-Subscribe Model(Mô hình Publish-Subscribe): Kafka flow theo mô hình Publish-Subscribe, nơi các publish phát các messages đến topics và consumers subscribe các topics để đọc messages.
High Throughput: Có thể hiểu đơn giản là Kafka có khả năng xử lý một lượng lớn dữ liệu, làm cho nó phù hợp với big data.
Scalability(Khả năng mở rộng) : Kafka có thể mở rộng dễ dàng mà không cần ngừng hoạt động, Cụm Kafka có thể tăng một node hoặc giảm một Node theo nhu cầu một cách dễ dàng.
Durability and Reliability(Độ bền và tin cậy cao), PERMANENT STORAGE: Kafka chạy hệ thống phân tán, dữ liệu được lưu trữ an toàn trong một cụm phân tán, đảm bảo sẽ lưu sẽ an toàn và không bị lỗi.
Dùng Kafka để làm gì ?
- Có thể sử dụng Kafka để xây dựng real-time streaming data pipelines và real-time streaming applications vì vậy nó có thể được sử dụng rộng dãi ở nhiều lĩnh vực.
- Message: Kafka cung cấp khả năng gửi và nhận Message hiệu suất cao, độ trễ thấp phù hợp để thay thế một số Message Queue truyền thống như RabbitMQ và ActiveMQ.
- Website Activity Tracking(Theo dõi hoạt động website): Kafka có thể sử dụng để theo dõi hoạt động real-time của người dùng trên các website, mobile, cho phép xử lý và giám sát hành vi người dùng ngay lập tức để phân tích và cá nhân hóa người dùn.
- Metric và ghi log: Kafka có thể giúp tổng hợp log và metric từ các hệ thống và ứng dụng... cung cấp một nền tảng tập trung để xử lý và giám sát.
- Stream Processing: Kafka được sử dụng với các hệ thống stream processing như Âpche Flink học Kafka Stream
- Event Sourcing: Kafka có thể lưu trữ sequence Event một cách an toàn, vì vậy nó hỗ trợ rất tốt cho Event sourcing application nơi các thay đổi trạng thái ứng dụng được lưu trữ dưới dạng Event.
- Commit log : Kafka có thể xử dụng như là một commit log cho hệ thống phân tán, đảm bảo dữ liệu được sao chép và nhất quán trên nhiều node.
Kafka hoạt động như nào ?
Kafka kết hợp cả hai Message model là Queue và publish-subscribe để cung cấp những lợi ích tốt nhất cho Consumers.
Nói qua lại về Queue
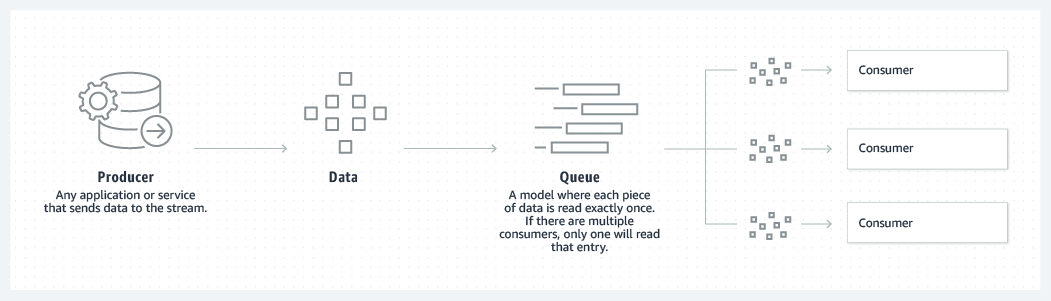 Queue cho phép data có thể được xử lý bởi nhiều Consumer instance(Mỗi một data sẽ có thể sử lý bởi 1 trong các consumer). Làm nó dễ dàng mở rộng.
Queue cho phép data có thể được xử lý bởi nhiều Consumer instance(Mỗi một data sẽ có thể sử lý bởi 1 trong các consumer). Làm nó dễ dàng mở rộng.
Nói qua lại về Publish-subscribe
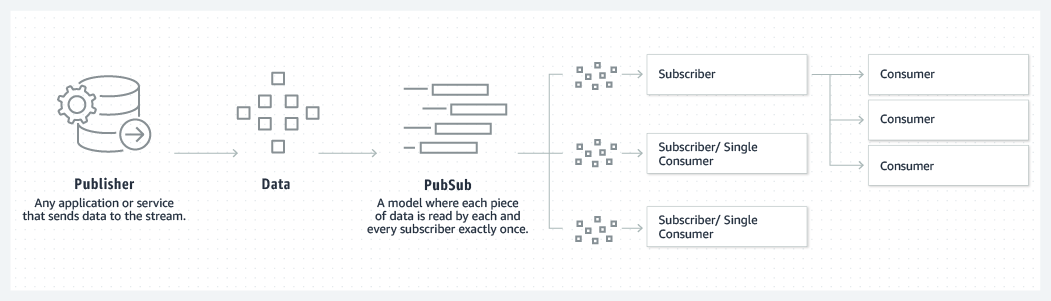 Publish subscribe cho phép data có thể được xử lý bởi nhiều Consumer khác nhau cho phép dễ dàng thêm logic xử lý mới.
Publish subscribe cho phép data có thể được xử lý bởi nhiều Consumer khác nhau cho phép dễ dàng thêm logic xử lý mới.
Cách kết hợp Queue và publish-subscribe của Kafka
Queue rất tốt nhưng Queue không thể có nhiều người subscribe, Nhưng Publish-subscribe để mọi tin nhắn đều được gửi đến mọi người subscribe nhưng không thể sử dụng để phân phối các công việc cho nhiều worker như Queue.
Cả 2 rất tốt nhưng Kafka rất tiếc.
Kafka sử dụng Partitioned log model để kết hợp cả Queue và publish-subscribe lại với nhau.
Log là một chuỗi các record được sắp xếp theo thứ tự và các log này sẽ được kafka gộp thành các segment và được lưu trữ trong các partition.
Segment là gì ?
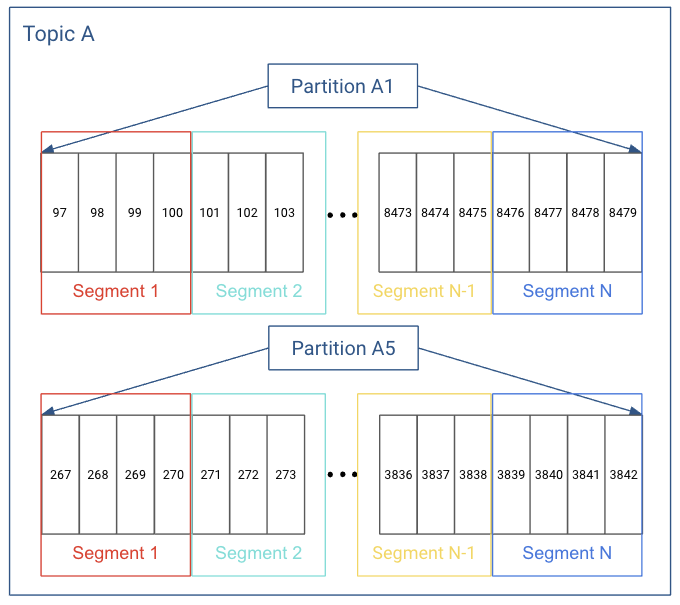 Trong thực tế, mỗi partition không lưu trữ tất cả records trong một file duy nhất.
Trong thực tế, mỗi partition không lưu trữ tất cả records trong một file duy nhất.
Kafka sẽ chia log thành các log segments. Mỗi log segments sẽ có thể được giới hạn size(Ví dụ 1G) và có thể giới hạn thời gian tồn tại ví dụ 1 ngày hoặc vĩnh viễn.
Mỗi một Partition được chia thành nhiều segments.
Và mỗi Partition sẽ lưu trữ 1 phần các record của topic chứ không lưu trữ tất cả.
Best nhất mỗi một partition sẽ tương ứng với một người subscribe (Một consumer đang consumer một Topic trên cùng một GroupId). Vì vậy nếu có 10 subscribe thì sẽ có 10 partition, cách này sẽ chia tải một cách hiệu quả để triển khai worker.(Tại sao ư ? phần khác nói nhé)
Điều này có nghĩa là có thể có nhiều người subscribe cùng một topic, và mỗi người được chỉ định một partition để có khả năng mở rộng cao hơn.
Cuối cùng: Kafka cung cấp khả năng phát lại, tức là cho phép nhiều ứng dụng độc lập đọc data stream theo tốc độ của riêng chúng. (Sử dụng offset)
So sánh Kafka và RabbitMQ
| Đặc trưng | Kafka | RabbitMQ |
|---|---|---|
| Kiến trúc(Architecture) | Kafka sử dụng Partitioned log model nó là sự kết hợp của Message Queue và Publish-subscribe | RabbitMQ sử dụng Message Queue |
| Mở rộng(Scalability) | Kafka cung cấp khả năng mở rộng cao bằng cách cho phép các partition đưược lưu trữ trên các máy chủ khác nhau | Tăng số lượng người sử lý Queue để mở rộng quy mô cạnh tranh xử lý. Đối với Topic thì sẽ tăng thêm Queue |
| Lưu trữ tin nhắn | Mặc định kafka sẽ lưu vĩnh viễn kafka cho đến khi đầy ổ cứng. Tuy nhiên chúng ta có thể cấu hình thời gian lưu trữ ví dụ 1 ngày, 10 ngày hoặc vĩnh viên | Dựa trên xác nhận(Acknowledgement) đã nhận Message, Message sẽ bị xóa sau khi đã nhận bởi consumer. |
| Multiple consumers | Nhiều consumer có thể đăng ký cùng một topic. | Nhiều consumer không thể đăng ký cùng một Queue, bởi vì Message sẽ bị xóa khi sử dụng, Nếu nhiều consumer đăng ký các consumer sẽ cạnh tranh để nhận Message |
| Replication(Sao chép) | Các topic sẽ được Replication tự động, dữ liệu của các Topic sẽ lưu trữ trên nhiều broker(Kafka node) nhưng cũng có thể cấu hình để các Topic không bị Replication | Không tự động Replication nhưng có thể cấu hình. |
| Message ordering | Dựa vào partition được 1 hay nhiều người đăng ký thì Consumer sẽ nhận được đầy đủ message hoặc cạnh tranh nếu có nhiều consumer cùng đăng ký một partition. (Consumer group) | Thứ tự Message được gửi đến theo thứ tự Consumer tham gia Queue, nếu có Consumer cạnh tranh, mỗi Consumer sẽ xử lý một số Message trên tổng số Message |
| Protocols | Kafka sử dụng Binary protocol thông qua TCP. | Sử dụng Advanced Message Queue protocol(AMQP) với sự hỗ trợ của các plugins |
| Performance | Kafka có thể truyền tải hàng triệu Message mỗi giây. | Có thể gửi hàng ngàn Message mối giây |
REF So sánh Kafka và RabbitMQ
https://aws.amazon.com/compare/the-difference-between-rabbitmq-and-kafka/https://aws.amazon.com/what-is/apache-kafka/
Tổng kết
- Apache Kafka: Là một Event stream platform, phát triển bởi LinkedIn, mã nguồn mở từ 2011.
- Kiến trúc: Hệ thống phân tán, bao gồm servers (brokers) và clients (producers và consumers).
- Đặc điểm: Hỗ trợ hệ thống phân tán, throughput cao, khả năng mở rộng, độ bền và tin cậy cao.
- Ứng dụng: Xây dựng pipelines và ứng dụng xử lý dữ liệu real-time, theo dõi hoạt động website, tổng hợp log và metric, stream processing, event sourcing, và làm commit log cho hệ thống phân tán.
- Hoạt động: Kết hợp mô hình queue và publish-subscribe thông qua partitioned log model, cho phép mỗi partition tương ứng với một subscriber.
- So sánh với RabbitMQ: Kafka mạnh hơn về scalability, lưu trữ tin nhắn vĩnh viễn, hỗ trợ nhiều consumers cho một topic, và có khả năng replication tự động.

Cập nhật lần cuối: